Ego-VCP:
Ego-Vision World Model for Humanoid Contact Planning
UC Berkeley, UM Ann Arbor, CUHK
ICRA 2026



1 University of California, Berkeley
2 University of Michigan, Ann Arbor
3 Chinese University of Hong Kong
Video
🔊 Sound on (recommended)
Abstract
Enabling humanoid robots to exploit physical contact, rather than simply avoid collisions, is crucial for autonomy in unstructured environments. Traditional optimization-based planners struggle with contact complexity, while on-policy reinforcement learning (RL) is sample-inefficient and has limited multi-task ability. We propose a framework combining a learned world model with sampling-based Model Predictive Control (MPC), trained on a demonstration-free offline dataset to predict future outcomes in a compressed latent space. To address sparse contact rewards and sensor noise, the MPC uses a learned surrogate value function for dense, robust planning. Our single, scalable model supports contact-aware tasks, including wall support after perturbation, blocking incoming objects, and traversing height-limited arches, with improved data efficiency and multi-task capability over on-policy RL. Deployed on a physical humanoid, our system achieves robust, real-time contact planning from proprioception and ego-centric depth images.
Highlights
Our world model and sampling-based MPC enables real-time visual contact planning for diverse object interactions in real-world scenarios, with only ego-centric depth camera and proprioception.
Methods
Multi-Task
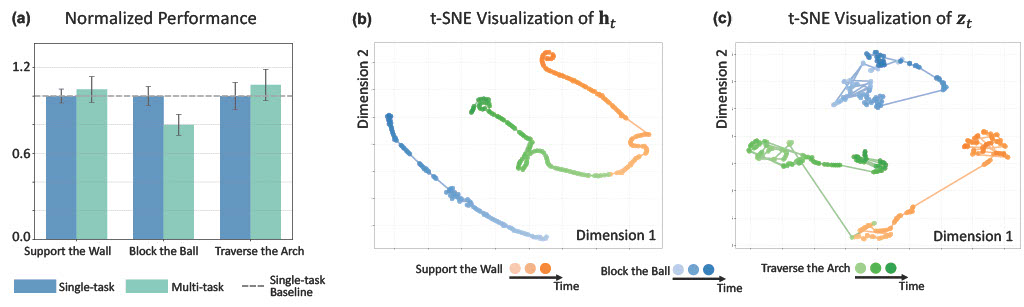
Multi-task performance and latent space visualization. (a) A joint model matches single-task performance. (b-c) t-SNE shows clear task separation: latent h_t captures evolving dynamics, while latent z_t encodes compact observations.
Reviewer Q&A
You might also ask questions like these:
Question
Discussion on computational cost and inference latency for onboard versus offboard deployment would help.
Answer
Our inference deployment runs on a laptop equipped with an NVIDIA RTX 2060. The high-level vision-based MPC plans at 25 Hz, and most of the runtime is spent on world-model inference. We have optimized the inference speed in our code; see the implementation details at GitHub: play_wm.py.
Question
Possibly restricted generalization due to offline dataset from random actions; additional discussion or validation under sensory noise or unseen dynamics would help.
Answer
We demonstrate that our method achieves stable contact planning using only noisy onboard camera observations, enabled by carefully designed domain randomization in simulation (see g1_wall_env.py#L690). Our experiments also show nontrivial generalization to out-of-distribution scenarios for example, the robot can block an unseen flying object (e.g., a box) and remain stable while a human passes through the scene.
Question
Additional explanation of how the world model and MPC collaborate would be helpful.
Answer
Our method uses a simple division of labor between the learned world model and MPC. At each timestep, we encode the current depth image and proprioception into a compact internal state. MPC then samples many candidate high-level action sequences and “imagines” their outcomes by rolling them forward through the world model in this latent space (without predicting full images). For each candidate, the world model provides a fast estimate of how good and safe the future will be, which MPC uses to score and refine the candidates (e.g., via CEM) and select the best sequence. Finally, we execute only the first action and repeat this loop at the next timestep, enabling real-time, feedback-driven planning.
Question
In Figure 5, comparing sample efficiency, why does PPO consistently appear below zero? Why do “Support the Wall” and “Block the Ball” suddenly rise to a “comparable level” after 1 million steps, while “Traverse the Arch” appears more stable? Additionally, the coordinate values across the three plots differ significantly in magnitude.
Answer
After 1 million steps, we rescaled the x-axis to show how much data PPO actually needs to match our method. As a result, PPO appears to have an abrupt jump in the plot. In practice, our method already achieves strong performance with only 0.2 million steps of data. As discussed in Section IV, different tasks use different objective functions (reward definitions), which highlights the multi-task advantage of our method. As a result, the value scale can differ across tasks.
Question
The fact that a longer planning horizon (Table I) leads to less good performance would suggest that the world model (either the dynamics or the reward model) is not predicting longer horizon well while Fig 7 claims the opposite. Do you know what is the reason for these seemingly opposing results?
Answer
In Section IV.D (Model Interpretation and Visualization on Prediction), our goal is to answer the following question: Does our model exhibit physical intuition, and does it efficiently extract a compact representation that retains only task-relevant information? The plotted trajectories show that the world model can capture the ball's parabolic motion while filtering out irrelevant noise, suggesting that the learned dynamics have not collapsed.
At the same time, no dynamics model is perfect. Moreover, in MPC it is not the case that a longer horizon is always better. Even with an analytical dynamics model, we typically do not use an excessively long horizon: increasing the horizon imposes a heavier optimization convergence burden for sampling-based MPC, and it can also amplify accumulated model errors. These two points are therefore not contradictory. The key takeaway from Table 1 is that multi-step prediction improves performance over greedy searching (horizon =1). The optimal horizon length is instead a trade-off among bias and variance, optimization landscape, and real-time constraints.
Acknowledgments
We would like to thank Jiaze Cai and Yen-Jen Wang for their help in experiments. We are also grateful to Bike Zhang, Fangchen Liu, Chaoyi Pan, Junfeng Long, and Yiyang Shao for their valuable discussions.
This project website is built with Next.js, adapted from the AIRIO website, and incorporates trajectory visualization methods inspired by DIAL-MPC.